Three ways to write a Fibonacci function in JavaScript
The Fibonacci sequence is one the most well-known calculations in the world of Mathematics. I won’t go into any more detail with regard to its significance, but I suggest that you read up on it if that kind of thing interests you — but only after you have finished reading this, of course!
Anyway, writing a function that can calculate the Fibonacci sequence is something that often comes up in the field of Computer Science. It may show up whilst learning recursion, or it may come up in a Software Engineering interview. Whatever the reason, it’s a useful, quite nice thing to know.
We are going to look at three approaches to calculating the Fibonacci sequence, and will discuss reasons why certain approaches are ‘better’ than others. Enough talk, let’s begin.
1. The Iterative approach

Here we have an approach that makes use of a for loop. Some things that worth noting about this implementation:
- We set up a
sequencearray that is already initialised with0,1,1. If theindexparameter passed in to the function is less than 3, we simply return1. There are other ways that this part could have been implemented, and there is also argument over whether the Fibonacci sequence should begin with 0 or 1. However, we’ve opted to just keep1as the lowest number. - Because we already have the first three values of the Fibonacci sequence in our
sequencearray, our for loop hasiset to2. You may wonder why we didn’t start at3— the reason for this is because, while we may have the first three values of the sequence already, we actually only have the zeroth, first and second values if we are referring to these values using a zero index. - In our loop, we push the value of
sequence[sequence.length — 1] + sequence[sequence.length — 2]into thesequencearray. This might seem a bit difficult to read because of all the of the sequence words, but we’re basically saying, given that the next value in a Fibonacci sequence is the sum of the two previous numbers in the sequence, that two two values, add them together, then push that into thesequencearray. - Finally, we gave our function’s
indexparameter a default value of1. This wasn’t necessary, but was just put in so that our function can still operate without a parameter passed in. We also use this same approach with the second and third examples.
Using the iterative approach is perfectly fine, as it does what we want it to, but it’s not particularly elegant. Let’s see if we can improve on that.
2. The Recursive approach

A recursive Fibonacci function is, in my opinion, one of the most elegant patterns in the programming world. We have a function that is just three lines long, yet is still expressive enough to anyone with an understanding of how recursion works. Let’s take a moment to break it down:
- As with recursive functions, we have a base case that prevents infinite loops. This base case of
if(index < 3) return 1;which we also used in our iterative Fibonacci function and the third example you will see later. - Finally, we return two recursive calls to
recursiveFib(). This works in much the same way that ouriterativeFib()function did, in that our loop returned a sum of the two previous numbers in the Fibonacci sequence. The difference here is that we calculate that same value through recursive calls to itself.
So while this recursive approach lends itself well to the calculation of the Fibonacci sequence — along with also being arguably more elegant — recursive functions can often being very memory intensive when left without certain mechanisms for handling this. If you’re not quite sure how recursion works, I high recommend reading up on the topic so that you can better understand how recursion affects the call stack — look up ‘call stack’ as well if you need to.
Anyway, because the function calls itself, which in turn calls itself, and so on until it reaches the base case, the number of function calls rises exponentially based on the original index parameter passed in. In short, your computer will likely hate you if you try to pass in any number above 50. So for that reason, our recursive Fibonacci function feels a bit redundant. Is there anything we can do to remedy this?
3. The Memoized Recursive approach
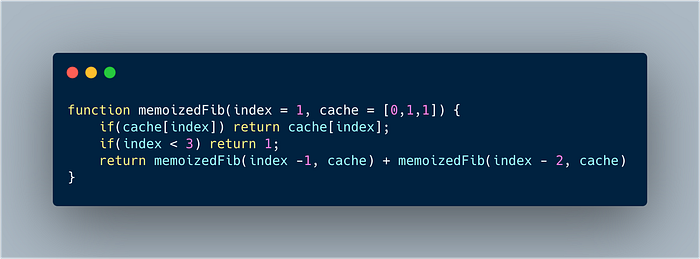
Memoization is essentially the concept of storing the output from a function so that it can be used again in the future. We basically retrieve the value from a cache instead of calling the function again. The concept of memoization is something that we can use to make our recursive Fibonacci function much more efficient. So how does this work?
- Our function now takes in two parameter instead of one. The first is
indexwhich is the same as before. The second iscache, which you will see that we default to an array of[0,1,1]. This is basically the same as what we did when we initialised thesequencevalue in ouriterativeFibonacci()function. Actually, we could have just set this up as an empty array in our memoized example, but I opted against this as it would have caused our array to have three empty values which I don’t particularly like the look of — I’ll explain more on why this happens later. - We then need an additional line of code which is
if(cache[index]) return cache[index]. Here we are basically saying, if we already have the value we need stored in our cache, return that value instead of having to go through computing it later. - The third line is our base case which we had also used in our previous Fibonacci functions.
- Finally, we return the value of what the sum of the two previous numbers in the Fibonacci sequence are. This is the same as what we had done in our previous recursive Fibonacci function. The key difference here is the number of recursive calls is reduced because we are caching each result and returning that, rather than calculating it each time. So if you imagine that we are returning the value of an index in the Fibonacci sequence by calculating the two previous values together, the first part of the sum will go through the recursive sequence to find each value, but the second part will simply rely on cached values.
This memoized approach means that our computer is much less likely to fail when it comes to processing large numbers passed in. Of course, you could argue that our iterative approach is the one that our computer is going to handle the easiest, but at the same time you could argue that our recursive calls are more elegant and easier to reason with.
And there we have it!
Three approaches to calculating the Fibonacci sequence. I hope you have managed to learn a thing or two and would love to hear your thoughts on which you prefer and why.

