Building a data layer with Vue and Composition API
When you are learning about a new frontend library, such as Vue or React you can read up a lot on certain best practices. There should be no problem finding resources on effective component composition, how to prevent performance bottlenecks, and the basics of state management, such as Redux, VueX, and so on.
But then, there’s an area that is hard to find any information for and that’s how to build a good data layer. It’s common to put a lot of care to optimize and organize the view layer but the data layer might get neglected and becomes a frequent source of bugs.
What is a data layer?
By a data layer, in the context of frontend applications, I mean actually three layers:
- Fetch layer — code that contacts the server, using XHR, Fetch or Websockets. Usually a set of services (classes) or pure functions.
- Normalization / Serialization layer — code that processes incoming and outgoing data.
- Store layer — code that handles saving and accessing data to a client-side store.
There’s surprisingly little information online on how to do these well. Maybe it’s because this logic is highly dependent on the design of your API and it’s hard to generalize. Yet still, I’ll try to provide some guidance.
Do you even need a data layer?
If a component directly does an ajax call and uses the raw response to render the data without storing it in any kind of client-side store that essentially means there’s no data layer involved.
In some cases that is fine, in a lot of cases not at all.
With this approach, problems might arise when…
- The same kind of request is being done in multiple places and the fetching logic needs to be reused
- Data coming from the server need to be processed.
- Some or all of the data might need to be reused elsewhere
- Data need to be used again, for example when the user goes back to the previous route and triggering the same request again would not be optimal.
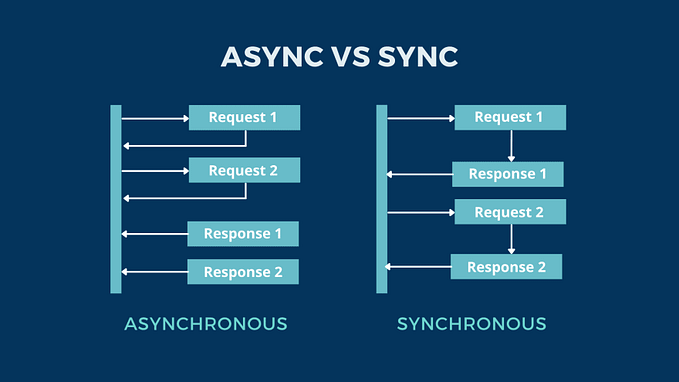
- There’s SSR involved and server state needs to be passed to the client
As more and more of these need to be covered, the complexity can grow exponentially. Handling these issues directly in a component can easily grow out of hand and so you have to start moving the logic elsewhere and start generalizing it — and that’s how the data layer slowly starts to form.
If your backend supports a conventional solution such as GraphQL or complies to a standard like JSON:API, you might save the majority or all of the work by using an existing data layer client, like Apollo or vuex-orm. Apollo requires a GraphQL backend, vuex-orm makes sense to use especially if your API is Restful.
If not and your backend is unconventional, the job is on you. That’s the case I’m gonna cover.
Fetch layer
Let’s start with a component that does an ajax request with Axios and passes the data to the template.
The component fetches and processes the result:
This is a very low-level approach to contacting an API directly in a component. We see a bunch of refs being used such as data error isLoading . We pass those to the template together withfetchUsers function itself — so that it can be triggered again if needed (letting user to retry for example).
Still, it’s a lot of code just to get some users and surely logic like this will be done at many places in the code.
At this point, we could introduce a 3rd party solution such as a util function from vue-use, vue-composition-toolkit, vue-concurrency to improve it. Or we could start using Suspense and instead of setting refs, use async/await directly in setup and return a Promise.
But for the purpose of demonstration, let’s refactor the previous code to a generic solution:
The generic ref setting logic was moved to a custom hook called useAsync and only the case-specific logic is passed into it via callback. The callback is expected to fire up some ajax and return back data.
Right away, I’ve also created a small normalizeUser function but there’s gonna be more work on that later.
Notice also the processError . Using this function on all responses from the server allows us to move towards consistent and unified error handling.
If this useAsync function is being used throughout the whole app, we’ve efficiently created a basic fetch layer. It might need some patches here and there due to the needs of serialization and store layers but the foundation is there.
Serialization layer
The purpose of the serialization layer is to process incoming and outgoing data and do at least some of the following:
- Validating the response has the right format (maybe via a tool like io-ts)
- Changing the structure so it fits the UI needs (maybe to make the data easily iterable)
- Serializing date strings into date objects
- Adjusting naming, perhaps changing snake_case to camelCase
- If needed, increasing naming consistency across different endpoints
- Removing data we don’t need. That makes clear what kind of data FE actually uses. Smaller objects are easier to work with and might have performance impact as well (potentially there’s less reactivity tracking)
Models sent in API responses tend to be quite big and have extra properties due to historical reasons or because those are needed by other clients — mobile apps, bots, 3rd party scripts.
Basic normalization function could look like this:
The output of this is a small and simple object that also provides some fallback values.
The serialization function, would do the opposite. Turn the “normalized” user back to the original format. You would use this when sending the user back to your API, perhaps when editing personal data.
Here this function is simpler, perhaps returning only a subset of things that the server expects the client to change. Images are left out because they are probably handled by a specific endpoint. In the case of a strict REST-API this would be okay to do with a PATCH request PATCH /users/1 . It would not work for a proper PUT request where the whole model is to be sent, not just a set of changes. Custom APIs usually also expect a set of changes, otherwise, they’d be RESTful:).
Store layer
If the data are being fetched and normalized to the simplest format they are ready to be stored.
At this point, there are some problems to figure out. How to store the data? How deeply nest? Store entities in a Map(Dict) structure or as an Array?
Let’s return to our previous solution of useAsync + fetchUsers . We passed a callback inside useAsync which called Axios and triggered normalization function. This function should now do one more thing: besides returning the data, also pass them to the store. In VueX this would mean pass them into some mutation.
This would be the most straightforward approach:
What’s happening here? We’re using two getters from store — hasUsers and users . hasUsers is a simple bool returning function that checks if valid users are in store. In the beginning, it could just look for truthy value in store, non-empty-array, or object. Later on, it might get more complex, checking even time of last fetch (if the users were loaded too long ago, they’re not valid anymore).
But at this point, we’re getting into a similar mess as before. As we start to handle more endpoints in new components, we’ll probably have to do something like this, over and over again:
- Check for valid value in the store, if present, return right away via store getters
- After success, commit the data to the store
A similar-looking code would get repeated over and over again and every time we’d have to think how to name the getters and mutations.
Couldn’t this be abstracted?
Yes, this is something we wouldn’t have to deal with if we were lucky to have a GraphQL backend and had an Apollo Client or if we had a RESTful, perhaps even JSON:API backend and using vuex-orm. In GraphQL land we’d just perform queries, in REST land we’d deal with consistent resources in CRUD way and it would be abstracted via an ORM.
If our API is custom, we can at least optimize logic that happens per every endpoint. Upon every endpoint call, we’re gonna check for existing value and maybe save a new one, or both (in case of a background reload).
Could our useAsync hook take care of it?
To some level yes, and at this point, we should probably rename it to something like useApi because it’s getting way more opinionated. Or better yet, compose the useApi on top of useAsync .
There are two approaches to how to go around this: convention or configuration.
Configuration: pass the getter and mutation names when calling useApi
Convention: derive the getter and mutation names — from one endpoint name or from a function name.
I usually prefer convention over configuration so I’ll go for the latter one.
In this case, useApi composes on top of useAsync . It requires a named function to be passed and derives store getter and setter names from it. Therefore it checks hasUsers and if returns true, it returns the Usersgetter. After success, it calls the setUsersmutation. Hitting a new endpoint then becomes a routine of creating a function X and creating getters and setters in the store of hasX X and setX . An alternative to this approach would be passing getter and setter names into useApi but from my experience a convention reduces overhead.
Folder structure?
Going forward with this approach it’s clear there’s gonna be some extra code for the fetching, serializing, and storing data. It could be stored right by side in a component, but what’s usually better is to create some kind of data folder.
Within that folder, there can be a list of files, one per every endpoint handler.
data
createUser.js
findUser.js
createPost.js
findPost.js
login.js
Each of these would have a normalizeReponse function, fetch function and a couple of mutations and getter functions that would be passed to the store.
If the logic bloats further, it’s possible to split things further:
data
createUser
fetch.js
serialize.js
store.jsBut from my experience, it’s hardly ever needed to go this deep!
Wrapping up
I hope this small insight has been useful. In reality a custom useApi function probably tends to bloat up, but it IS possible to create something flexible, helpful, and easy to maintain — a custom high-quality data layer.
Subscribe on herohero for weekly coding examples, hacks and tips
Hey 👋 If you find this content helpful, subscribe to me on herohero where I frequently share concise and useful coding tips from my day-to-day experience working with JavaScript and Vue.